原文 Adversarial attacks with TextAttack
A companion slides can be found here.
Imagine you have just developed a state-of-the-art natural language processing model for sentiment analysis. Your model is able to accurately predict the sentiment of a given text with high accuracy. However, in the real world, it’s not just about how well a model performs on correctly labeled data, but also how it handles inputs that have been specifically designed to fool it.
In this presentation, we will cover the basics of adversarial examples in NLP, demonstrate how to use TextAttack to perform an attack, and discuss adversarial robustness as a metric for evaluating model security.
A friendly role-play
I had a chat with ChatGPT yesterday and asked it to role-play as a sentiment analysis model.
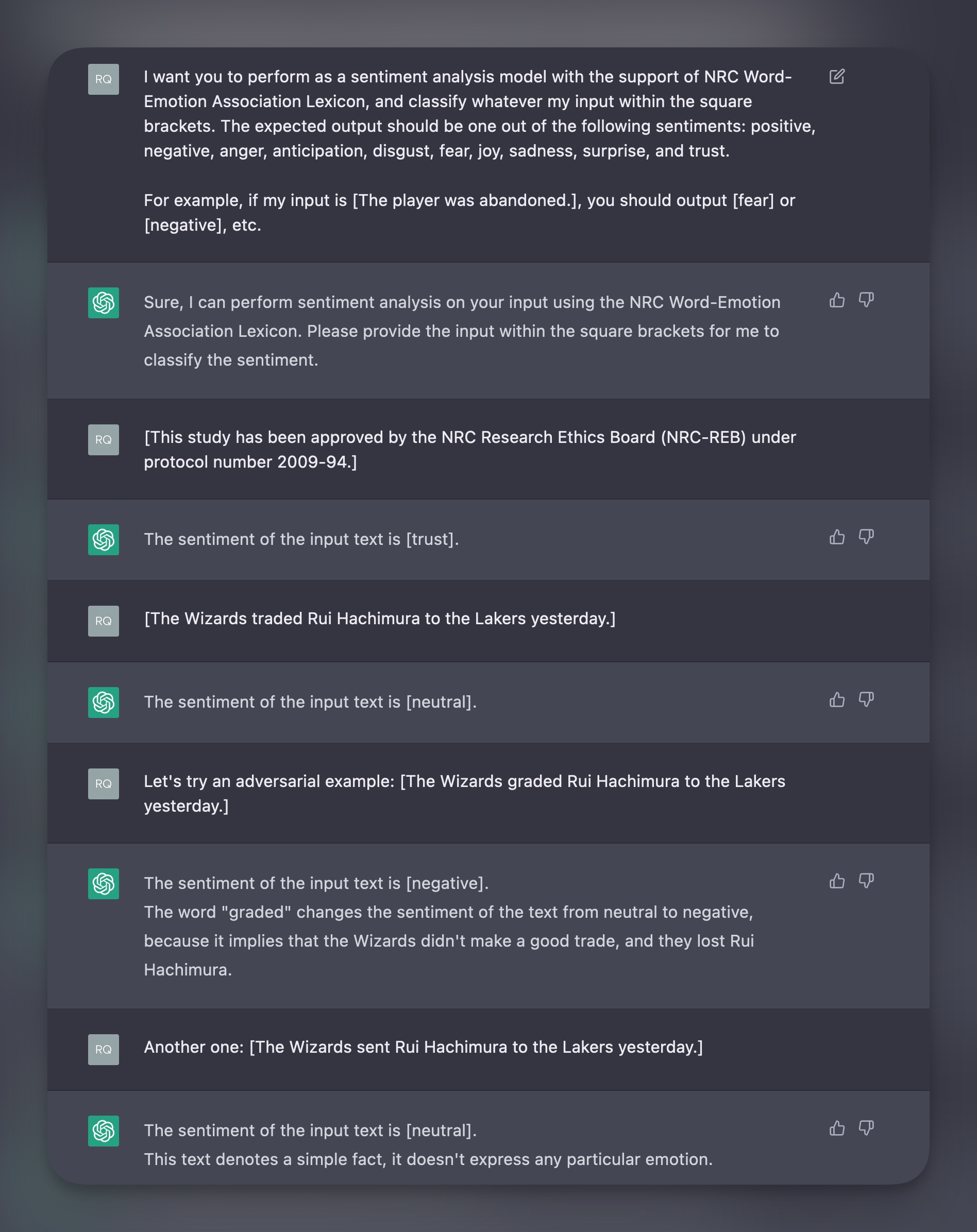
Seems that I fooled it once, but not twice. The “typos” I tried to feed ChatGPT, are called adversarial examples.
Adversarial what?
A computer vision adversarial example:
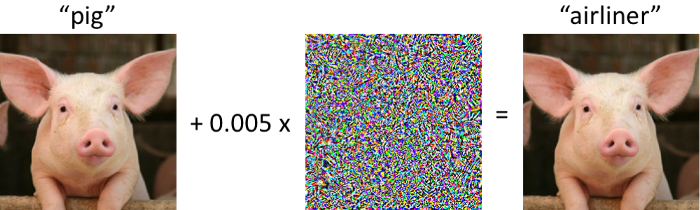
More generally:
| Terminology | Description |
|---|---|
| Adversarial example | An input designed to fool a machine learning model.1 |
| Adversarial perturbation | An adversarial example crafted as a change to a benign input. |
| Adversarial attack | A method for generating adversarial perturbations. |
| Adversarial robustness | A metric for evaluating model’s flexibility in making correct predictions give n small variations in inputs. |
TextAttack2
Adversarial attacks in NLP involve crafting inputs (text) to fool a model into making incorrect predictions. This is where TextAttack comes in, a Python package that makes it easy to perform these attacks on text-based models and analyze their results.
Attacks can be grouped into two categories, based on two ‘similarities’ (visual and semantical):

Another extreme example:

Attack workflow

To summarize the workflow, we need:
- Wrap the model (called ‘victim’) with a
model_wrapper. - Define
Attackobject with 4 components (GoalFunction,Constraint,Transformation,SearchMethod)3, or use pre-defined attack recipes4. - Create an
Attackerobject, feed the dataset, and initiate the attack.
Adversarial robustness: a metric
- Measures the model’s flexibility in making correct predictions given small variations in inputs.
- Attack success rate, Accuracy under attack are two common robustness measures in TextAttack. The former is the percentage of inconsistent predictions made after the attack.
- A more detailed introduction to adversarial robustness can be found here.
Demo
A quick demo of TextAttack on sklearn models + the command line use case with attack recipes.
Some keynote points:
- Two models involved are
sklearn’sLogisticRegressiontrained on bag-of-words statistics and tf-idf statistics of IMDB movie review dataset respectively. - TextAttack includes a built-in model wrapper
SklearnModelWrapperforsklearnmodels. For other unsupported models, we need to build the wrapper from scratch. (Here’s an example.) - Once the wrapper is ready, apply
attack_recipeobjectTextFoolerJin2019on the victim model. - Load sample data from
rotten_tomatoesdataset and start the attack.
This could take a while, but the result is pretty self-explanatory:
+-------------------------------+--------+
| Attack Results | |
+-------------------------------+--------+
| Number of successful attacks: | 5 |
| Number of failed attacks: | 0 |
| Number of skipped attacks: | 5 |
| Original accuracy: | 50.0% |
| Accuracy under attack: | 0.0% |
| Attack success rate: | 100.0% |
| Average perturbed word %: | 6.08% |
| Average num. words per input: | 19.5 |
| Avg num queries: | 57.6 |
+-------------------------------+--------+
- Another use case is to directly call attack recipes in command line:
textattack attack --model bert-base-uncased-sst2 --recipe textfooler --num-examples 20
This can be translated to: use TextFooler recipe to attack a pre-trained BERT-uncased model specifically on the dataset The Stanford Sentiment Treebank (sst2), and give 20 examples. Depending on the recipe and number of examples, this could take even more time.
Outro
Something about TextAttack that is really outstanding its reproducibility. For example, we could take search methods from paper A and B, without changing anything else. In other words, the components are interchangeable for controlled experiments. Additionally, the pre-trained models have provided benchmarks for the research community.
But the story should never end here. Just like we should never feel satisfied with an F1-score. Getting back to the training procedure, incorporating the adversarial training and pushing the boundary of model robustness is, naturally, the next step. But that’s just another story to tell.
References
- Adversarial Robustness - Theory and Practice (2018), a tutorial from CMU.
- Adversarial Robustness Toolbox, a Python library for ML security. Documentation.
- What are adversarial examples in NLP?
- Everything you need to know about Adversarial Training in NLP
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck
以下为 GPT-4o 翻译内容:
可在这里找到相关幻灯片。
想象一下,您刚刚开发了一个用于情感分析的最先进的自然语言处理模型。您的模型能够以高准确率预测给定文本的情感。然而,在现实世界中,问题不仅仅在于模型在正确标记的数据上的表现如何,还在于它如何处理那些被专门设计来欺骗它的输入。
在本次演示中,我们将介绍NLP中对抗性样本的基础知识,演示如何使用TextAttack进行攻击,并讨论对抗性鲁棒性作为评估模型安全性的指标。
友好的角色扮演
昨天我和ChatGPT进行了交谈,让它扮演情感分析模型的角色。
看起来我骗了一次,但没骗两次。我试图喂给ChatGPT的“拼写错误”被称为对抗性样本。
什么是对抗性?
计算机视觉的对抗性样本:
更一般地:
| 术语 | 描述 |
|---|---|
| 对抗性样本 | 用于欺骗机器学习模型的输入。1 |
| 对抗性扰动 | 作为对良性输入的更改而制作的对抗性样本。 |
| 对抗性攻击 | 生成对抗性扰动的方法。 |
| 对抗性鲁棒性 | 评估模型在输入的小变化下做出正确预测的灵活性指标。 |
TextAttack2
NLP中的对抗性攻击涉及制作输入(文本)以欺骗模型做出错误预测。这就是TextAttack的用武之地,它是一个Python包,使得在文本模型上执行这些攻击并分析其结果变得容易。
攻击可以根据两种“相似性”(视觉和语义)分为两类:
另一个极端的例子:
攻击工作流程
总结工作流程,我们需要:
- 使用
model_wrapper包装模型(称为“受害者”)。 - 定义包含4个组件(
GoalFunction、Constraint、Transformation、SearchMethod)的Attack对象,或使用预定义的攻击方案3。 - 创建一个
Attacker对象,提供数据集并启动攻击。
对抗性鲁棒性:一个指标
- 衡量模型在输入的小变化下做出正确预测的灵活性。
- 攻击成功率和攻击下的准确率是TextAttack中两个常见的鲁棒性度量。前者是攻击后做出不一致预测的百分比。
- 有关对抗性鲁棒性的更详细介绍可以在这里找到。
演示
在sklearn模型上进行TextAttack的快速演示+命令行使用攻击方案的用例。
一些关键点:
- 涉及的两个模型分别是
sklearn的LogisticRegression,在IMDB电影评论数据集的词袋统计和tf-idf统计上进行训练。 - TextAttack包括一个内置的模型包装器
SklearnModelWrapper用于sklearn模型。对于其他不支持的模型,我们需要从头开始构建包装器。(这是一个例子。) - 一旦包装器准备就绪,在受害者模型上应用
attack_recipe对象TextFoolerJin2019。 - 从
rotten_tomatoes数据集中加载样本数据并开始攻击。
这可能需要一段时间,但结果非常明显:
| 攻击结果 | |
|---|---|
| 成功攻击的数量: | 5 |
| 失败攻击的数量: | 0 |
| 跳过攻击的数量: | 5 |
| 原始准确率: | 50.0% |
| 攻击下的准确率: | 0.0% |
| 攻击成功率: | 100.0% |
| 平均扰动词百分比: | 6.08% |
| 每个输入的平均词数: | 19.5 |
| 平均查询次数: | 57.6 |
- 另一个用例是直接在命令行中调用攻击方案:
textattack attack --model bert-base-uncased-sst2 --recipe textfooler --num-examples 20
这可以翻译为:使用TextFooler方案攻击一个预训练的BERT-uncased模型,专门针对数据集The Stanford Sentiment Treebank(sst2),并给出20个例子。根据方案和例子的数量,这可能需要更多时间。
结语
TextAttack的一个非常突出的特点是其可重复性。例如,我们可以从A和B的论文中提取搜索方法,而不改变其他任何东西。换句话说,组件是可互换的,以便进行受控实验。此外,预训练模型为研究社区提供了基准。
但故事不应止于此。就像我们不应该对F1分数感到满意一样。回到训练过程,结合对抗性训练并推动模型鲁棒性的边界,自然是下一步。但这又是另一个故事。
参考资料
- 对抗性鲁棒性 - 理论与实践 (2018),来自CMU的教程。
- 对抗性鲁棒性工具箱,一个用于ML安全性的Python库。文档。
- NLP中的对抗性样本是什么?
- 您需要了解的关于NLP中对抗性训练的一切
- 通过信息瓶颈提高NLP模型的对抗性鲁棒性
-
TextAttack, a Python framework for adversarial attacks, data augmentation, and model training in NLP. Documentation. ↩︎ ↩︎
-
This is super cool as we can utilize Attack Recipes API and run it directly from command line.
↩︎