Adversarial attacks with TextAttack
A companion slides can be found here.
Imagine you have just developed a state-of-the-art natural language processing model for sentiment analysis. Your model is able to accurately predict the sentiment of a given text with high accuracy. However, in the real world, it’s not just about how well a model performs on correctly labeled data, but also how it handles inputs that have been specifically designed to fool it.
In this presentation, we will cover the basics of adversarial examples in NLP, demonstrate how to use TextAttack to perform an attack, and discuss adversarial robustness as a metric for evaluating model security.
A friendly role-play
I had a chat with ChatGPT yesterday and asked it to role-play as a sentiment analysis model.
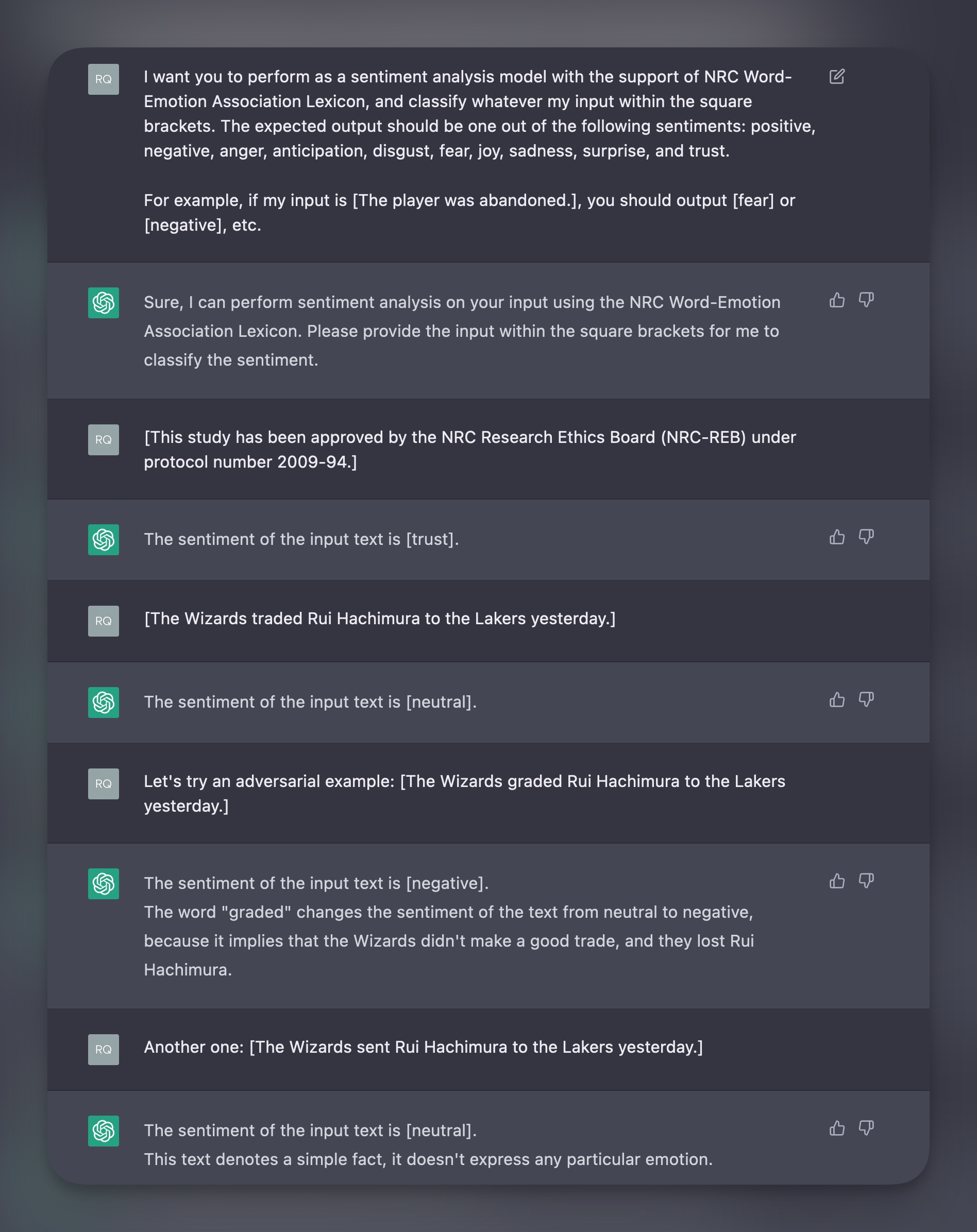
Seems that I fooled it once, but not twice. The “typos” I tried to feed ChatGPT, are called adversarial examples.
Adversarial what?
A computer vision adversarial example:
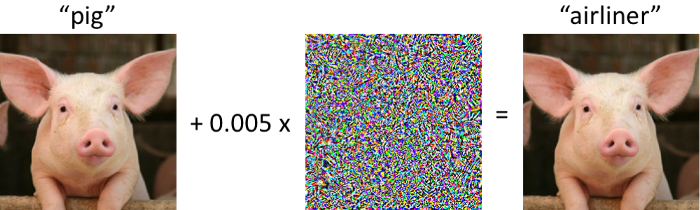
More generally:
| Terminology | Description |
|---|---|
| Adversarial example | An input designed to fool a machine learning model.1 |
| Adversarial perturbation | An adversarial example crafted as a change to a benign input. |
| Adversarial attack | A method for generating adversarial perturbations. |
| Adversarial robustness | A metric for evaluating model’s flexibility in making correct predictions give n small variations in inputs. |
TextAttack2
Adversarial attacks in NLP involve crafting inputs (text) to fool a model into making incorrect predictions. This is where TextAttack comes in, a Python package that makes it easy to perform these attacks on text-based models and analyze their results.
Attacks can be grouped into two categories, based on two ‘similarities’ (visual and semantical):

Another extreme example:

Attack workflow

To summarize the workflow, we need:
- Wrap the model (called ‘victim’) with a
model_wrapper. - Define
Attackobject with 4 components (GoalFunction,Constraint,Transformation,SearchMethod)3, or use pre-defined attack recipes4. - Create an
Attackerobject, feed the dataset, and initiate the attack.
Adversarial robustness: a metric
- Measures the model’s flexibility in making correct predictions given small variations in inputs.
- Attack success rate, Accuracy under attack are two common robustness measures in TextAttack. The former is the percentage of inconsistent predictions made after the attack.
- A more detailed introduction to adversarial robustness can be found here.
Demo
A quick demo of TextAttack on sklearn models + the command line use case with attack recipes.
Some keynote points:
- Two models involved are
sklearn’sLogisticRegressiontrained on bag-of-words statistics and tf-idf statistics of IMDB movie review dataset respectively. - TextAttack includes a built-in model wrapper
SklearnModelWrapperforsklearnmodels. For other unsupported models, we need to build the wrapper from scratch. (Here’s an example.) - Once the wrapper is ready, apply
attack_recipeobjectTextFoolerJin2019on the victim model. - Load sample data from
rotten_tomatoesdataset and start the attack.
This could take a while, but the result is pretty self-explanatory:
+-------------------------------+--------+
| Attack Results | |
+-------------------------------+--------+
| Number of successful attacks: | 5 |
| Number of failed attacks: | 0 |
| Number of skipped attacks: | 5 |
| Original accuracy: | 50.0% |
| Accuracy under attack: | 0.0% |
| Attack success rate: | 100.0% |
| Average perturbed word %: | 6.08% |
| Average num. words per input: | 19.5 |
| Avg num queries: | 57.6 |
+-------------------------------+--------+
- Another use case is to directly call attack recipes in command line:
textattack attack --model bert-base-uncased-sst2 --recipe textfooler --num-examples 20
This can be translated to: use TextFooler recipe to attack a pre-trained BERT-uncased model specifically on the dataset The Stanford Sentiment Treebank (sst2), and give 20 examples. Depending on the recipe and number of examples, this could take even more time.
Outro
Something about TextAttack that is really outstanding its reproducibility. For example, we could take search methods from paper A and B, without changing anything else. In other words, the components are interchangeable for controlled experiments. Additionally, the pre-trained models have provided benchmarks for the research community.
But the story should never end here. Just like we should never feel satisfied with an F1-score. Getting back to the training procedure, incorporating the adversarial training and pushing the boundary of model robustness is, naturally, the next step. But that’s just another story to tell.
References
- Adversarial Robustness - Theory and Practice (2018), a tutorial from CMU.
- Adversarial Robustness Toolbox, a Python library for ML security. Documentation.
- What are adversarial examples in NLP?
- Everything you need to know about Adversarial Training in NLP
- Improving the Adversarial Robustness of NLP Models by Information Bottleneck
-
TextAttack, a Python framework for adversarial attacks, data augmentation, and model training in NLP. Documentation. ↩︎
-
This is super cool as we can utilize Attack Recipes API and run it directly from command line.
↩︎